| 3. XMLmind XML Editor-friendly content models | ||
|---|---|---|
 |  | |
| 3. XMLmind XML Editor-friendly content models | ||
|---|---|---|
| | | |
Validating a document against a RELAX NG schema is similar to matching some text against a regular expression. If the document ``matches'' the schema, the document is valid, and this, no matter which sub-expressions were used during the match.
Example: string "b" matches regular expression "(a?,b)|(b,c?)" and we don't care if it matches sub-expression "(a?,b)" or sub-expression "(b,c?)". The situation is exactly the same with RELAX NG schemas, simply replace the characters and the character classes used in a regular expression by RELAX NG patterns.
The job of a RELAX NG schema is a validate a document as a whole, and that's it. For XXE, the problem to solve is different. One of the main jobs of XXE is to guide the user when she/he edits an XML document. That is, one of the main jobs of XXE is to identify the content model of the element which is being edited, in order to suggest the right attributes and the right child elements for it.
To do that, XXE needs to know precisely which ``sub-expressions were used during the match''. Unfortunately, sometimes, this is impossible to do.
All examples used in this section are found in XXE_install_dir/doc/rngsupport/samples/
RELAX NG schema, target.rnc:
start = build-element
build-element = element build {
target-element*
}
target-element = element target {
attribute name { xsd:ID },
element list { ref-element* }?,
element list { action-element* }?
}
ref-element = element ref {
attribute name { xsd:IDREF }
}
action-element = element action { text }Document conforming to the above schema, target_bad.xml:
<build> <target name="all"> <list> </list> </target> <target name="compile"/> <target name="link"/> </build>
If you open target_bad.xml in XXE and select the list element, XXE randomly chooses one of the two list content models. This is correct because both list content models are fine in the case of an empty list element. However there is a drawback: if XXE chooses the kind of list which contain action child elements, you'll have no way to insert ref child elements in an empty list. In other words, one content model hides the other one.
Now, if you open target_good.xml in XXE, there is no problem at all:
<build> <target name="all"> <list> <ref name="compile"/> <ref name="link"/> </list> <list> <action>cc -c *.c</action> <action>cc *.o</action> </list> </target> <target name="compile"/> <target name="link"/> </build>
However, in the vast majority of realistic cases, XXE knows how to make a difference between two child elements having the same name and having different content models.
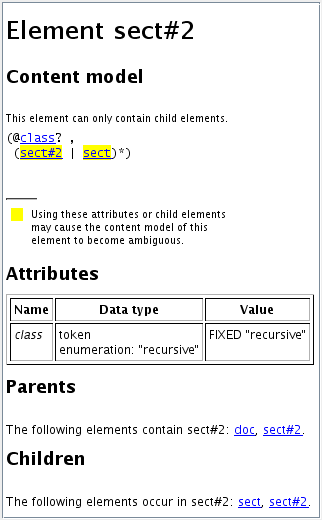
RELAX NG schema, sect.rnc:
start = doc-element
doc-element = element doc {
(simple-sect|
recursive-sect)+
}
simple-sect = element sect {
attribute class {"simple"}, paragraph-element*
}
recursive-sect = element sect {
attribute class {"recursive"}?, (recursive-sect|simple-sect)*
}
paragraph-element = element paragraph { text }Document conforming to the above schema, sect.xml:
<doc> <sect> <sect></sect> <sect class="simple"> <paragraph>Paragraph 2.</paragraph> </sect> </sect> <sect class="simple"></sect> </doc>
In the above example, XXE has no problem at all making a difference between the empty <sect> element and the empty <sect class="simple"> element. The reason is obviously because the first kind of sect element has a required attribute class with simple as its fixed value.
RELAX NG schema, name.rnc:
start = names-element
names-element = element names {
name-element+
}
name-element = element name {
element fullName { text } |
(element firstName { text } & element lastName { text })
}Document conforming to the above schema, name.xml:
<names> <name><fullName>John Smith</fullName></name> <name><firstName>John</firstName><lastName>Smith</lastName></name> <name><lastName>Smith</lastName><firstName>John</firstName></name> </names>
XXE allows to replace the firstName, lastName pair by a fullName. Simply select both child elements and use command → . But it is impossible to replace a fullName by a firstName, lastName pair.
The only way to do this is to select the fullName to be replaced and then, to use command → [1]. This will force XXE to enter the so-called “lenient” editing mode. Suffice to remember that in this mode, the user is not guided. The user may add or remove any child elements she/he wants, including a firstName, lastName pair[2].
Note that the above example is not specific to RELAX NG. It is possible to model this kind of content with a DTD or a W3C XML Schema.
The example below is very similar but can only be expressed using a RELAX NG schema. This is the case, because, unlike a DTD and a W3C XML Schema, a RELAX NG schema can be used to specify the places within an element where text nodes may occur.
RELAX NG schema, name2.rnc:
start = names-element
names-element = element names {
name-element+
}
name-element = element name {
text |
(element firstName { text } & element lastName { text })
}Document conforming to the above schema, name2.xml:
<names> <name>John Smith</name> <name><firstName>John</firstName><lastName>Smith</lastName></name> <name><lastName>Smith</lastName><firstName>John</firstName></name> </names>
The situation is worse with the name2.rnc example than with the name.rnc example. It is always allowed to delete a text node and this includes the text node containing "John Smith". That is, there is no way to force XXE to enter its “lenient” editing mode in order to be able to replace text node "John Smith" by a firstName, lastName pair.
In such case, using named element templates is the only way to cope with such content models. Simply specify two named element templates for element name, one containing a text node with a placeholder string and the other containing a firstName, lastName pair.
[1] This menu item is available only after you check "Enable the 'Edit|Force Deletion' menu item" in → , General|Features section.
[2] The right approach here is to define two named element templates for element name, one containing a fullName child element and the other containing a firstName, lastName pair.
| | | |
| 2. Specifying which RELAX NG schema to use for validating a document |  | 4. Known problems |
![[Tip]](images/tip.svg)